Information Field Theory#
Theoretical Background#
Information Field Theory [1] (IFT) is information theory, the logic of reasoning under uncertainty, applied to fields. A field can be any quantity defined over some space, e.g. the air temperature over Europe, the magnetic field strength in the Milky Way, or the matter density in the Universe. IFT describes how data and knowledge can be used to infer field properties. Mathematically it is a statistical field theory and exploits many of the tools developed for such. Practically, it is a framework for signal processing and image reconstruction.
IFT is fully Bayesian. How else could infinitely many field degrees of freedom be constrained by finite data?
There is a full toolbox of methods that can be used, like the classical approximation (= Maximum a posteriori = MAP), effective action (= Variational Bayes = VI), Feynman diagrams, renormalization, and more. IFT reproduces many known well working algorithms, which is reassuring. Also, there were certainly previous works in a similar spirit. Anyhow, in many cases IFT provides novel rigorous ways to extract information from data. NIFTy comes with reimplemented MAP and VI estimators.
Tip
A didactical introduction to information field theory can be found in [2]. Other resources include the Wikipedia entry, [3] and [4].
Free Theory & Implicit Operators#
A free IFT appears when the signal field  and the noise
and the noise  of the data
of the data  are independent, zero-centered Gaussian processes of known covariances
are independent, zero-centered Gaussian processes of known covariances  and
and  , respectively,
, respectively,

and the measurement equation is linear in both signal and noise,

with  being the measurement response, which maps the continuous signal field into the discrete data space.
being the measurement response, which maps the continuous signal field into the discrete data space.
This is called a free theory, as the information Hamiltonian

is only of quadratic order in , which leads to a linear relation between the data and the posterior mean field.
In this case, the posterior is

with

the posterior mean field,

the posterior covariance operator, and

the information source.
The operation in  is also called the generalized Wiener filter.
is also called the generalized Wiener filter.
NIFTy permits to define the involved operators ,  , , and implicitly, as routines that can be applied to vectors, but which do not require the explicit storage of the matrix elements of the operators.
, , and implicitly, as routines that can be applied to vectors, but which do not require the explicit storage of the matrix elements of the operators.
Some of these operators are diagonal in harmonic (Fourier) basis, and therefore only require the specification of a (power) spectrum and  .
Here
.
Here  ,
,  , and
, and  is the power spectrum of the process that generated as a function of the (absolute value of the) harmonic (Fourier) space coordinate
is the power spectrum of the process that generated as a function of the (absolute value of the) harmonic (Fourier) space coordinate  .
For those, NIFTy can easily also provide inverse operators, as
.
For those, NIFTy can easily also provide inverse operators, as  in case
in case  is unitary,
is unitary,  .
.
These implicit operators can be combined into new operators, e.g. to  , as well as their inverses, e.g.
, as well as their inverses, e.g.  .
The invocation of an inverse operator applied to a vector might trigger the execution of a numerical linear algebra solver.
.
The invocation of an inverse operator applied to a vector might trigger the execution of a numerical linear algebra solver.
Thus, when NIFTy calculates , it actually solves  for
for  behind the scenes.
The advantage of implicit operators compared to explicit matrices is the reduced memory consumption;
for the reconstruction of just a Megapixel image the latter would already require several Terabytes.
Larger images could not be dealt with due to the quadratic memory requirements of explicit operator representations.
behind the scenes.
The advantage of implicit operators compared to explicit matrices is the reduced memory consumption;
for the reconstruction of just a Megapixel image the latter would already require several Terabytes.
Larger images could not be dealt with due to the quadratic memory requirements of explicit operator representations.
The demo codes demos/getting_started_1.py and demos/Wiener_Filter.ipynb illustrate this.
Generative Models#
For more sophisticated measurement situations (involving non-linear measurements, unknown covariances, calibration constants and the like) it is recommended to formulate those as generative models for which NIFTy provides powerful inference algorithms.
In a generative model, all known or unknown quantities are described as the results of generative processes, which start with simple probability distributions, like the uniform, the i.i.d. Gaussian, or the delta distribution.
Let us rewrite the above free theory as a generative model:

with  the amplitude operator such that it generates signal field realizations with the correct covariance
the amplitude operator such that it generates signal field realizations with the correct covariance  when being applied to a white Gaussian field
when being applied to a white Gaussian field  with
with  .
.
The joint information Hamiltonian for the standardized signal field reads:

NIFTy takes advantage of this formulation in several ways:
All prior degrees of freedom have unit covariance, which improves the condition number of operators that need to be inverted.
The amplitude operator can be regarded as part of the response,
 .
In general, more sophisticated responses can be obtained by combining simpler operators.
.
In general, more sophisticated responses can be obtained by combining simpler operators.The response can be non-linear, e.g.
 , see demos/getting_started_2.py.
, see demos/getting_started_2.py.The amplitude operator may depend on further parameters, e.g.
 represents an amplitude operator with a positive definite, unknown spectrum.
The log-amplitude field
represents an amplitude operator with a positive definite, unknown spectrum.
The log-amplitude field  is modelled with the help of an integrated Wiener process in order to impose some (user-defined degree of) spectral smoothness.
is modelled with the help of an integrated Wiener process in order to impose some (user-defined degree of) spectral smoothness.NIFTy calculates the gradient of the information Hamiltonian and the Fisher information metric with respect to all unknown parameters, here
and , by automatic differentiation.
The gradients are used for MAP estimates, and the Fisher matrix is required in addition to the gradient by Metric Gaussian Variational Inference (MGVI), which is available in NIFTy as well.
MGVI is an implicit operator extension of Automatic Differentiation Variational Inference (ADVI).
The reconstruction of a non-Gaussian signal with unknown covariance from a non-trivial (tomographic) response is demonstrated in demos/getting_started_3.py. Here, the uncertainty of the field and the power spectrum of its generating process are probed via posterior samples provided by the MGVI algorithm.
Output of tomography demo getting_started_3.py |
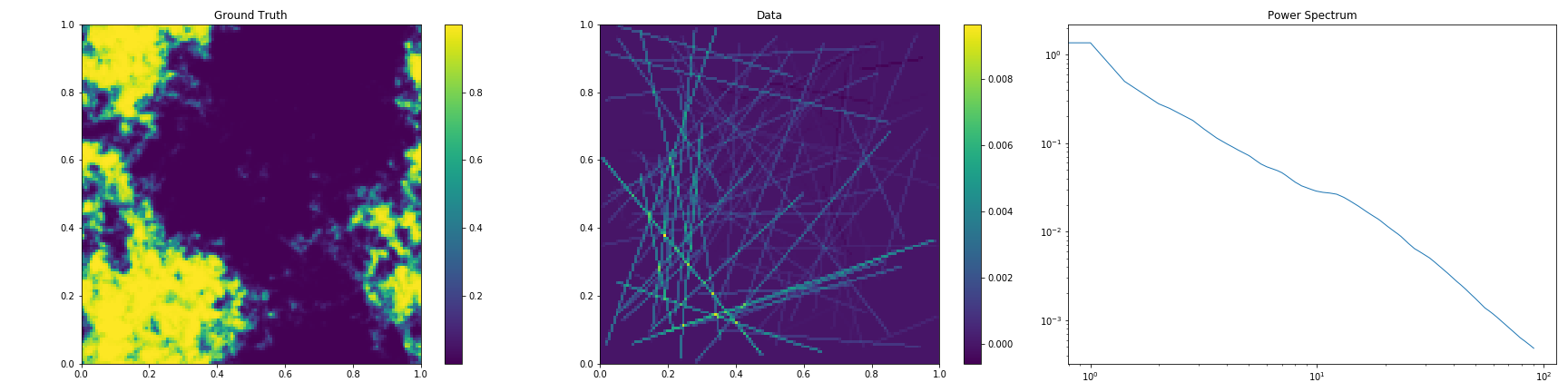
|
Non-Gaussian signal field, data backprojected into the image domain, power spectrum of underlying Gausssian process. |
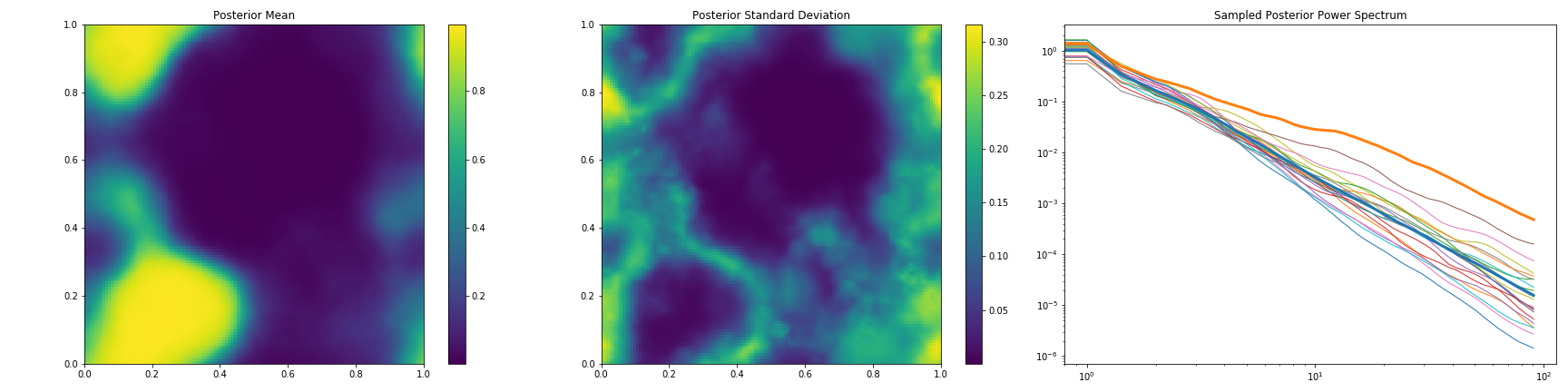
|
Posterior mean field signal reconstruction, its uncertainty, and the power spectrum of the process for different posterior samples in comparison to the correct one (thick orange line). |
Maximum a Posteriori#
One popular field estimation method is Maximum a Posteriori (MAP).
It only requires minimizing the information Hamiltonian, e.g. by a gradient descent method that stops when

NIFTy8 automatically calculates the necessary gradient from a generative model of the signal and the data and uses this to minimize the Hamiltonian.
However, MAP often provides unsatisfactory results in cases of deep hierarchical Bayesian networks. The reason for this is that MAP ignores the volume factors in parameter space, which are not to be neglected in deciding whether a solution is reasonable or not. In the high dimensional setting of field inference these volume factors can differ by large ratios. A MAP estimate, which is only representative for a tiny fraction of the parameter space, might be a poorer choice (with respect to an error norm) compared to a slightly worse location with slightly lower posterior probability, which, however, is associated with a much larger volume (of nearby locations with similar probability).
This causes MAP signal estimates to be more prone to overfitting the noise as well as to perception thresholds than methods that take volume effects into account.