Discretisation and Volume#
Note
Some of this discussion is rather technical and may be skipped in a first read-through.
Setup#
IFT employs stochastic processes to model distributions over function spaces, in particular Gaussian processes  where
where  denotes the covariance function.
The domain of the fields, and hence , is given by a Riemannian manifold
denotes the covariance function.
The domain of the fields, and hence , is given by a Riemannian manifold  , where
, where  denotes a Riemannian metric.
Fields are defined to be scalar functions on the manifold, living in the function space
denotes a Riemannian metric.
Fields are defined to be scalar functions on the manifold, living in the function space  .
Unless we find ourselves in the lucky situation that we can solve for the posterior statistics of interest analytically, we need to apply numerical methods.
This is where NIFTy comes into play.
.
Unless we find ourselves in the lucky situation that we can solve for the posterior statistics of interest analytically, we need to apply numerical methods.
This is where NIFTy comes into play.
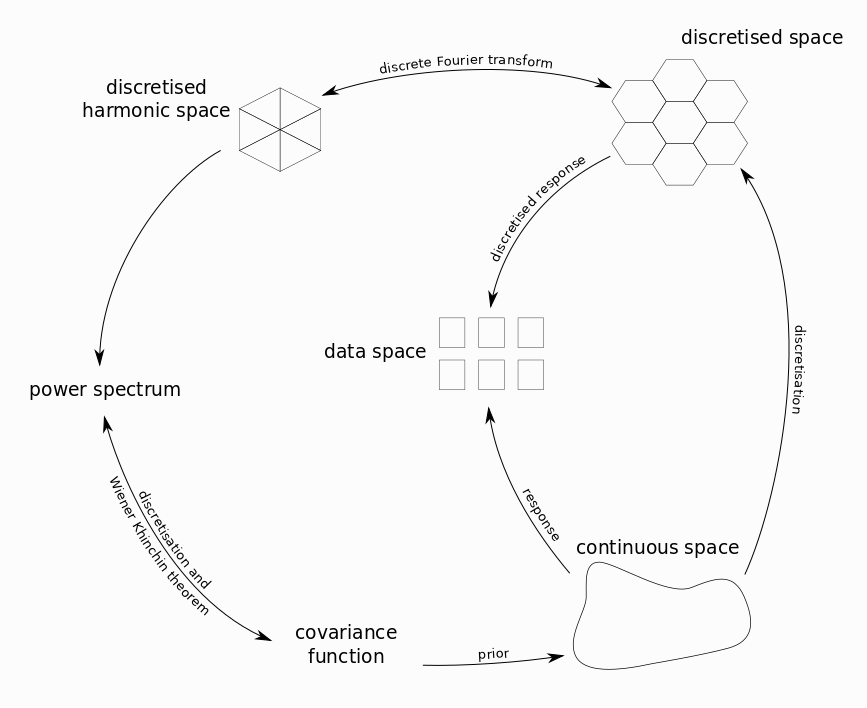
Figure 1: Sketch of the various spaces and maps involved in the inference process.#
A typical setup for inference of such signals using NIFTy is shown in figure 1.
We start with a continuous signal  , defined in some function space
, defined in some function space  over a manifold with metric .
This is measured by some instrument, e.g. a telescope.
The measurement produces data in an unstructured data space
over a manifold with metric .
This is measured by some instrument, e.g. a telescope.
The measurement produces data in an unstructured data space  via a known response function
via a known response function  and involves noise
and involves noise  with known covariance matrix
with known covariance matrix  .
In the case of additive noise, the result of the measurement is given by
.
In the case of additive noise, the result of the measurement is given by

Discretisation and index notation#
To compute anything numerically, we first need to represent the problem in finite dimensions.
As for stochastic processes, several discretisations of  like collocation methods, expansion into orthogonal polynomials, etc. can be used (see [1], [2] for an overview and further information about their reliability).
In particular, NIFTy uses the midpoint method as reviewed in section 2.1 of [1] and Fourier expansion.
like collocation methods, expansion into orthogonal polynomials, etc. can be used (see [1], [2] for an overview and further information about their reliability).
In particular, NIFTy uses the midpoint method as reviewed in section 2.1 of [1] and Fourier expansion.
Without going into the details, discretisation methods basically introduce a finite set of basis functions  , where
, where  denotes a generic index set with
denotes a generic index set with  being the chosen discretisation dimension.
Any Riemannian manifold is equipped with a canonical scalar product given by
being the chosen discretisation dimension.
Any Riemannian manifold is equipped with a canonical scalar product given by

Projection to the finite basis is then given by

where the Einstein summation convention is assumed and we defined the volume metric

along with its inverse,  , satisfying
, satisfying  .
.
Obviously, the basis needs to be chosen s.th. the volume metric is invertible, otherwise we run into trouble.
Volume factors are encoded into the  .
For specific choices of the basis , e.g. indicator functions in the case of a pixelation, the entries of are indeed just the volumes of the elements.
Lowering and raising indices works with and just as usual.
.
For specific choices of the basis , e.g. indicator functions in the case of a pixelation, the entries of are indeed just the volumes of the elements.
Lowering and raising indices works with and just as usual.
After projection, any function  is represented by its approximation
is represented by its approximation  , where
, where

which defines an embedding  .
.
Changes of base are performed by reapproximating the in terms of another basis  :
:

which in general implies additional loss of information unless the two bases are compatible, i.e. encode the same information. The latter is e.g. true for regular collocation grids on tori and the associated cropped Fourier series. The discrete Fourier transform then maps between those bases without loss of information.
Discretisation of operators works in the same way by expansion.
For illustration purposes, let  be a (not necessarily linear) operator.
The result of its action on functions
be a (not necessarily linear) operator.
The result of its action on functions  is known and may be expanded in , i.e.
is known and may be expanded in , i.e.
![A[s] = (A[s])^k \, \phi_k \, ,](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAIoAAAAWBAMAAADtDRlvAAAAMFBMVEX///8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAv3aB7AAAAD3RSTlMAv0h0nYsY+6/pz/PdYDJ3bjFDAAAACXBIWXMAAA7EAAAOxAGVKw4bAAACGklEQVQ4y62UwUsbQRTGn5vMmmzdMXgoqFCW/gOOlBS8BUSvLkJEPMgWhR60pCAtPeZSSKGiKPXQUzxEtBeDB68K3jWgJ8E2eFKLGKogXqTvze5mdyeupeAcXmbe9+ZH5u03A/D/YzYHTzCM2lNQ2mOVtgrFiaKSnvYnPTYGtg5J/JkxRx9EWGC4s7KiuOsuf2KAngHo/zkoV4lobZ+IoSRlB7TrgAJZgG6vLyxaPJKLoaRd1k2IgqmtPVe9jNSyt8UYSlbGsU8hSkro1f5TuRKR2ql0OYayT0EX30MUs6wV30jD8K5Ibc5YJJ3lJ1XKe3kg2JCUfL5u+Dnq7fzoi1CpZrVV3b59dik9P3Cs06xK4SX0EiVhp2yiNLxtFb12HrIxg2SDKF8sR/kvfJGiDSNESS3p8twfvV27Ceh0AhuPl75Kyu9boVA0orBS6YAofGdOUrZd7VmNQcFp2lgXYN5L/ayhUHQ60RTArzoJfAFCfSk4DAYCG6On+R/U0wILlL7QDjz5lYXCMt6fEKUT3sFW08bkCf0adQPMnPqNVvBT4AUq0FHLcEQUvuvdGvHaEK6N+Rpc3DlwfIfdNw+zLX4ZBL65AubmNxROXtnSD7anDVWGPRtrH5pvxoOuu1CuJVZ1OH7KpsZJGycepwRbmpQAjBfAs/E/KDzTQnnuZ8x6mPcYBQ5VCrMCs7ZSvLcuo1B49K1bDRKR8ReTToIklZwdKwAAAABJRU5ErkJggg==)
where the domain of the operator may be restricted to the image of the embedding given above. Integrals can now be written as
![\left< s , A[t] \right>_{\mathcal{M}} \approx s^i \left< \phi_i , \phi_j \right>_{\mathcal{M}} (A[t])^j \equiv s^i \, v_{ij} \, (A[t])^j \, ,](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAWoAAAAXBAMAAADQPRh7AAAAMFBMVEX///8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAv3aB7AAAAD3RSTlMAzzKdYOmv3YtIv3QY8/sDkd+RAAAACXBIWXMAAA7EAAAOxAGVKw4bAAAEVUlEQVRYw9VXT2gcVRj/dmZ2d2Znkl0CatBAJ9R66KWpFhEqdmlFRKHZ/rFE7CGCFkuRLvagUMFJBBMhh72IWEFSL22oaQeDodAgUxpKIYX04KUQMO2h1NbDghfFHvy+92d33szOy5jiwQc7+/bt7/eb7733ve/7HsCmmhvAY7XyZiXL8H9uheTAWZy0/SRUNqbWeo4miNcSumZew7TEYQU6J2wpQMXXKE7Qw2DIMLbJ3Gq/x9S6ut4s2nA8QzI3cVcc6fzNQDcR5IxnG233Rfg069SPuaPNNRQiB8V04TLAzGKGZG5iQ4H+wUCnCNTQrPU2ehTZgte7o8/2UCymdHEkupAhmZdoKSszc4+B/iLQLo3VH9Djta5X8Bb22L3LKd0Swg5mSOYlFuJe6IUHCOSsE+iqqvLKA9zCJfFjjfxigHrbWx2EMce/FeJHKV0LrVin0XMfU4O4ZD4iD4DT08J0E55AkPX+kQBBZcXRzIHnHoqDgfDzRGjiZ/H1M3La7ntffs8l48T1lC4OOc3EwgrJb2e9u7mI0xTfS2Ke38A8WVYOaGruSCJA7p+7PgtduI3PQrBsSDce9OrcNxXirZQutMEcSWYYJumFv8HhXEQ0vvS2J5AB7CFQ1WcgZUEoPnz4gHoSTrs0hb78iLug3XShGrHRGJHPSdX93SwmoqqQtJw2PE9qzY2I+Kfx60Nh2bFjnxFoP889GUFEwumQ/wKB94gP99VtWI2SQcRppHXXyrvZf091/FpKlmqdQKojAlDYNk7y/grAqI+gdxnImFWMvXjHF6dRwEstQIsDV9i4GtnwE59WjOjdSunKE6WsxEkx847VeuJ2gHegn/fRaXa0EDTmhQVmFcAbNGPalsrM8tmlFdp7CSfj2l69r2WzM1qFZbjNkhcRLbJ8UrxJ1e1htZSsRo6Pal+0NiKWaQf2wXDEq67VEH/eNkVQR1fGzyg/zeDN34mAw+WRuOBGz0CwZgzhtMKlQsiSFxFLuFRWGztHU7qGdPtu5JOSVdyvYM1eGdcS8W0YCV69EsB3ARhbjoK1ZQxBCz8SaIEQeyJw3lIXhuAy/JgTn0d4cJz7+POlwZd58iKiid7+FfnO7pSunS5JpaR7As1oeJVQS6S3NZW8Bp1iBYboeyqE4QlNrUuhBaOW26lIDnKifRqMwZpSnEndcqQt9VCNRQoN0RUZrofVHk3H2lrzai9m1bg+T+h9N7jVIU8OjLh3J1w1x5WUI18+rC9QUa0f9ERXVBPxckKATDLCNtqF6HyGPpUwe+mgTjKDLVohTF6MGOyAoUqgBBT58h/0VqPa16AnhrK2Sltd5Lnl0ACcznpBo1OnhrJOxeTFiEFxp19mi/9mQtdubXgfeAH0RNQ1et5lnmbjNwP42YdPstTT9wZKXkj00GfuUh6GmH5MV99GeGH374miXQoAU+25KP8tlievyp8YTaDy6ebuhKfCx7tTOpsltuA/bf8AQAoznyxXeY8AAAAASUVORK5CYII=)
where the appearance of the volume metric can be hidden by lowering the first index of the operator,
![(A[w])_k := v_{km} \, (A[w])^m \, .](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAALsAAAATBAMAAAA68WHaAAAAMFBMVEX///8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAv3aB7AAAAD3RSTlMAGJ3PYOl0i90y+/NIv69ILDK6AAAACXBIWXMAAA7EAAAOxAGVKw4bAAACLElEQVQ4y42VsUvkQBTGvyS77mY364UrRHYRgsi1rt6BlRKwsjjwT0hnFQlaaCGy21wdWOSuUPSaAzsPLC0CcsVdoR7H9QvKcZVooSBY+N4kG5OdYckUszPvfd9vh5e8CaA5iEdjIf6tLEFHoSFZsdkHxd7e+J/Xk4gRC6JkISLaVSG8bEUbU0DwrHfqSWBGzJdeFo+1QnjZSvixAFbHcFtJYFXMs04OXy6El62Ep6ju1G0/3tOfcb2b/Rx+3CtAV1gZ/w9G1MIHkUQ15Hmi3M7hS+0CeIWV8cuo4gLTkdjXxOwYq6SxfDS8Zsjio0RuHb/iKN0MM3iFlfG17BHEE7aixglpJupRLSq7jL9L0uYc/rynscTn5ORoK+PfZPF7on7Q70jjHuIQujj9V0w6w8VwLymZCSus4vR2xvODp93b/6zBNbZJz/jvMFyp2NecdEdZGV/P4vn91DyUnlhzivkEf5QvYTxOKVkbaZVqzxu6A8xn1tyTaj/Bt0o7sSKtPaV/cnjQ8wqrhC/boke1R9Yca98Q8MLswF95Fz/a13FPSQoPel5hZfyXVN+zoXvoPdhYfghI83HrfMNmcSXAX3f4xcQ6wSg86HmFlfFbqf5XCLOdv6DiRdXG2SdlL1F40PMKK+O7OX1Xhe9BO/H3VXcwhdOe76rwZr7hD1T437D6U44Cz+G05w9U+IadM5Q8GV+JCt2YspXwO0OicPhrtQiz2NdKsmLzCtlbCS9JopIVW9DXfAAAAABJRU5ErkJggg==)
Hence, the volume metric need not be carried along if the operators are defined in this fashion right from the start. Linear operators mapping several functions to another function are completely specified by their action on a given basis, and we define
![A^k_{\,\,mn\ldots} := (A[\phi_m,\phi_n,\ldots])^k \, .](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAANEAAAAWBAMAAACs+WTQAAAAMFBMVEX///8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAv3aB7AAAAD3RSTlMAv0h0nYsY+6/pz/PdYDJ3bjFDAAAACXBIWXMAAA7EAAAOxAGVKw4bAAACl0lEQVRIx7WVTWgTQRTH/9kv6W6zKVUEK5bVS3oouDko9RZoFG9dgooUD1ta8BBLvQieJNBLDhZysQdBCJWICrWhdyFQ8agLpZceahQ9GBRLK0Iv4nykycy666qQt+yyM/Pe/N7MvPcG4HIrjz6J8Upum0G/SFiVm0f6BsJtuVlKFxMM5g5/Rry/REyXQc7EaGw53a6Ug9zOZIJdjX2HOz+uPKjGmMyQoVMfe8pnXZxIOieNKSj7HVJoXXoMSfWQeiT0TOWxvpFAGuC875xkhxz7GrcNVVjjvSXpN8tGI/fhz6Rz7HvtLieFd8uNIy2ipI52z2l2oKaUZxIS6g3LDfchJ713pEF7OI60jTHjWLcjb1YjFZV74VjV8IzZT2ydbonxsFQcjSFJ2aM4qUYkyX6CkedEntIGUzmDk9Te9OZt0bm6EXyOIWXkuNF2E3ODz+xhitrfIOfyQ5igqSLjx6xJ7L9euZ9MUihJr1TeUvuX8AyBZAU6FmJIltBvuEj/TK6TdPdmgXct1AjFU6tzS7lPE2xswddxwbi8eTzhnDSyNXtxgN450Ygg4fnNIfa7RmA53p7WtJhSBvNY1zPOYgKJJIqxT+sa9VHyjERET5ZBEx4LLrE/qvqPoTTNoMR0Uu5508U4VtAmeyW8hPSlY05a7QMf2wdkDuaj5JkU5ZOw15aRXntA7LXpKz60vOXnoNwhYxfrl4ACWXaWzJNtdV9CutoxzwpZwX2knkVKW9wTWuZMp4RVj1cLWgVX0i+CUK0gmq+jSijzsRC+Tg5l0Bfs6fSDGEPB4SQKaBp1/EayaxFTcR+pZy3QJ5xQQwJpR6546Vb05VFDKir4uY/Usw32hGVTIHkySUccqYj/EPvf79whcWt+ASjZsDAPSZLLAAAAAElFTkSuQmCC)
If  is a (linear) integral operator defined by a kernel
is a (linear) integral operator defined by a kernel  , its components due to are given by
, its components due to are given by
![A^k_{\,\,ij\ldots}
&= v^{km} \, \left< \phi_m, A[\phi_i,\phi_j,\ldots] \right>_{\mathcal{M}} \\
&= v^{km} \, \int_{\mathcal{M}} \mathrm{d} x\,\sqrt{|g|}\,\left(\prod_{n}^{|\{ij\ldots\}|}\int_{\mathcal{M}} \mathrm{d} y_n \, \sqrt{|g|}\right) \,\,\phi_m(x)\, \tilde{A}(x,y_1,y_2,\ldots)\, \phi_i(y_1) \, \phi_j(y_2) \cdots \, .](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAqMAAABfCAMAAADrjj4RAAAAPFBMVEX///8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAo1xBWAAAAE3RSTlMAv0h0nYsY+6/pz/PdYDLjcJHTX+i7bQAAAAlwSFlzAAAOxAAADsQBlSsOGwAADQRJREFUeNrtXYm2rKgOVSYVhTf4///6ZFJAEI6ltr6VrL6r+lhEdsk2JGFqmkDYRJqz8osuCEi1cPHP6IKA1Ep3ly7/481aTq/5RZT36nbQtP8H0iLVX4+NoOhkX691GekFbiXFffClXDmKq4B4nM4p4Fpg6lathBb+vKBZtTluhST43B2MLm1m1JCpacbgS7L6AbQKiMfRnAL9C0dRD038eSGzinja4bxPaXXRpD1TFnJ0WA2qqAKycTSnIMVfOLoBAPmqUNYpSzOiCZ+9hdUlC8VGtlhV/zvR1/bQFkhT9A3qcfLQkIN8UxhuBq5dysWXPOePOl2OtA3lwu+LuXMHZYtqgGwczSmUbhRzlHFo5Y/39EtLDtprY+0fs5xIWUzWSac7GeePEJ9Dk7V9/RJVHYYvFojjaE6hfKNdSmFi0MyfDpgWPrVjjc/JV+lXw9ct2sd+LDU2ldOGiUYONUD4kUL5RnuOYhhh+LY3qmOVU6piCcSV9qFNM2aUTsaLnFkFEB4pYM91CG801XG0XA7kzRTtF5nmk9o9b0qJIGPwRqHLsTxHPSD8QKF8oxRHIbL/dsCkDOK8mkJjs2rtjmJMgaO9Hh9QlFrK4aEGCM8rlG+U4qiEoaZvB0yqDeeKQHnvj5oeFx2HL4Yfi31cvMhmXAL/9GCUD4QHCg31w3Lv+mJ6UR1HXTnhuEph6OkzYj09Np/MjFqr1hQd0hY3mDUcq+LeYJTkLAGERwoj20pu1xvKFM/dF+lPHnT1vY0NxQxN/xGRfB5UQ4rl0zJN26wK+7TmgXBxWNIE9oRySjR7/MEo1NEEEB4q6BjelvSvM0XY9QvUycQnD8J6YrxYNIB/+uUgf7FZxj5dJ9MWt2uiBINROB/oOIWehiW3t2KQuVsEt3LGuqF6NExyCkn9L5vWwdmn68QONLl7hoNRBxx1X40sLLmpdE0NR5mLAIUkXI86EZhl8mExNmu4NKQwA/ZCbmZ1G4zC+UBnVWh1hLOWXK9rr6EweK9utU7moktMpq1qS6GlvyvGZin7JL1/P8rQZDNUBxylmZLbdUKqODp4mgNRVn3C0NLfFW2ztH1S7ej+/epA/BVE1Tx8Ujb3lLdr9Uy/fVhHUhPY0a8L+cTw9vS3CdntTE0yQP0/TDL5OEMvdkffIgia9v9GJgLeGggICAgICAgICAgICAgIyOPysqQZgiUqIJG0b5sq0sJaP5BARPc2RKyDgQMQXzq1uKpqkPOxkVA6QrOAbNLr+U2mdyVqakxq+SDVm0c81wWP0NuDrCJnsXL0IFgR/FGO4hlmr4A4MdvwWI7m14KgZznajLBsGsS5mHZp68bR9PLBpzlKwZCCOG/UBvVmaj7PLh/Ui0yfdBJn8EhBbFDfbhzV60Fyywf7Xj7KUd5B44CY2ARtHGX6lJPM8sFJPGtHxQw79IIE1mrzR9PLB3XI/2j328FifhDt9bU7jqaXDz4dMy21wsY9X5KW3LQgE68bVkW5p93ywSxHb8NGobP/EkXpXZmYdr2vpp+c3B87dzSXw78Pm5whRfoZYTNDN/lm4zoubsdCzd7S++WDuE+Phd6Irelg0P4zQob72M9fi005pJDG/4oMt03vFHP/WmzKEQGH9DNd/W1N1c/4tdhU0ARDTR+RG0eu+Sxfi02dggoZ0o8IH883ckKCkCmRgkzpZK0lH38nYhYjm2Hb6Df041O5Ozs/3sJLRm5OjYmjafbI0c/zKNj12GowzpcN2fdDL+G8ibNNVPTn5GmvrHhyDZvH9OWQo/QGbFUYu6tGmhBrRAtLpE5K2VLg02EJLxkONKfn3UccFTdgq8I4zGD6XtDXj42gKHP0kpH2bFgi9eB7dLOIYvw3jra/hkwJjN5f0x9eARZYdFJb8FIh9QArFE5o3CK4FZLg4OilWMZMhyeGQk+oO7fIUEYL6TKjjdUczWErg8tjnPy0QyY1lrgcvm2sTda0L3itxWkPYPK/KlRpPCCtOXvZP3pp5xwOWWewEI41JY6SHzl6EHjLKo6mMAYczbjC+8skAhkff4Uc3cmd4wJRrfQAYFGhTuMBGZHeNj88eim0SNmZFQUamAVJhxztM8NMtRzNY6vkaArj5LsS6a5N7hENhQvE3eredNaQhTn8VaFK4xl3dPFDUXT0UsQjeooG9nClQ47mOFDL0Ty2Oo4mMU7ldwhXWJc+KERZ1z9hhoJacYX5yyrUaTwgqF8cDBIdvRSxKnts7jENelHmKP+Ro3lsdRxNYixzVO7TSNMuASB8b47hZuCZgpeKX2sAM1dvVqFK41Zuql6ddTXPK50jFD2lWH+jEgKCtrv4evI/2FKcsQRH6U8czeQvV3D6ZyY9mAOMU8Ffxr2gqI0enU3h+Q+jC6Nhu41AouDWIgmopZ+weyQZmF3ubjmFCo0r46Ld2eDLa6023Roq3HeZTLObJfCGBkvARZvR3mqdy+kmgOoWlwNb3gh6NUfT2DZw9mfGQ2kFjAWOcqrOOJeRVzbaBvUehvf+oAVFO+YKei2yQGV4Cg2wvY5pX0PUeQ9Td9pjrpY59bumvcZW/zNLaMQSZqomqLCjyRQm032s7k6JClmZCwhx67Leg2+qBkUG/U3UrWZyO5UcTadXN3D2Z0Z74JUwToe5MToZty1MzMp1r5XtYXQsCJfJnCvotcgCFeNh31IdksoUV8xDtLXGME29qVoyCrGGV7/VkCNKfl7nW/OmfIC9oQhJxdPMc/nIxhTmlstT6rW/PnXebOAYcvRf879/4WgSWwBO/UwUvfcljB7E/8z/3SVChH5uLOQoWvFuD2NcS9B+EbOCL1VwaxENNTLR9rpSpBVb99paY5iu3n0tGYVYw6vfaqBOJD+vyzmJSo4mh1rE7IclAw5yLCxIUOgVx4N7K661o+lhIB+c+plkasw4GqvDeGhHdRsuz20xQ/7g3JZY3h5G5/XXGpZs0gW3FlHDKDFH1+tqF4xaf9SDaVwfV+++lr2C2cdop7HW/4w/akw6qguZWKo7lY4GiwujSpDtK+KbKN3irWrpgabi+p84msTmg9NPfvGl9DjaljM5xnjc1ys3V6i8chMMznW2Z/YeRucFTBoQatIFN5Jozznk6HZ9YQ2r5WgAU6t1uVp2Cm4foy5X/1P7t9jXppxBTIcluqNS5oiOy3/Lx0Z3HRsMQeisd3EyTuCVMVMG2wZOP3nNDT2OhuowHnO0xQ1mDVd89wfnBlVb8DDcEleXZ7R7r8UFpZsb6KBa9uyvmx/grmc+Xa0eTHO/gaVqSSrYfYxiDfcAZdnjkPyKmee4r0sm50ZyKMEYzxOSPZaix563jBZKYRKmd3qKSddczdHsKJMDp3ot2uvIjgSv/yHGIK7f966Eckp0E/iDczpFEDwMa6Yln3Vji+WTJgqijjqn1UC17NlfJ0jt1+KuI5s4jD7XzmGDabYmsjmMqJakgt3HKNYw9fv9Tz612T05X4zMfx4XGSa/mSc/SNuPM/3C0TpspDUmQHBvpO8I41QKylyt/uCc3GUYMidE7wviEOoSHyevC7fd1eEwz8R2MM3WRFu9YS0JBfs6Rxpr/a87+vrEgiM8k37f/iNOcLT/aZypjE0lgDvbfzNO6zAGHE29BXhT2wbn4paTvMwi/3YrVNF3xlkIr0u1hKUvcdSv1ZVrze10vbtaUgpuN+1AY61fvm6N13giYRuEMpMJmV06Lp739MuckjI2rlrorxiDOSUJQojkmxHP529z1kamp8PtoBauZ8JjloWp693dLalg9zEqarxE5hOnafkmSrU4bjHtmxRH8U9z88rYKM0dl36AMZibJ/JdfUzdcA5JPp8dFnSc20EtXE//XnQAU9Ub3y2lsO1jVNJ4h8if92hAR3+KX9aK/I4tDcr7a5j/0CIy+8dRwWub66/fphS8fYzkk+BPh//37tQh03OU2ewtyGznTBIV37+LyAi7O75f+psbKbt2ebYTcBidc2uX+/sJNMN24++Xydo54fzGi9eIdwd7QOgzGg72gLgbG+wB8Q2xk8ebfnQO5MXvwA+Lg+/GBnvpfEKks192FgYaLjYsP+xMdzs2nUUFDrxdsDNNVK/Mk5xebFh+2JnudmzK44W9HV8vrW12IdU8DcbDtOIlhpq/Fhsc2vANd9QlkvVUN85yozY/1DC+FxvsNf52GXo7dV7zoBn0GXTT1etWz5mqZ7DBmQ1vl5HaVmd63gw2czOutlXnzpd5MzaQ5wT1ZuKhm0Cng+f26olZLGurovUd/wA2cEc/xNZbXYqczxet7/gHsEF2FMR2qLksfrS+43ERM4bmAdGdfS5lFK3veFxaGKwHKVAhXt/xtMAgE4gVmYue4/UdDwuBQ+5AVi5Or4Q1QnIUZDOkbzxwQ4AZBfE80jca0jvPIQX5XmjfvW88h8JQPUjQr47ve23gwC+QsLd/W8fKoacHib2/dy2JRRM0yY/yPzH8f/5UwA15AAAAAElFTkSuQmCC)
Resolution and self-consistency#
Looking at figure 1, we see that the there are two response operators:
On the one hand, there is the actual response of the instrument used for measurement, mapping the actual signal to data.
On the other hand, there is a discretised response  , mapping from the discretised space to data.
Apparently, the discretisation and the discretised response need to satisfy a self-consistency equation, given by
, mapping from the discretised space to data.
Apparently, the discretisation and the discretised response need to satisfy a self-consistency equation, given by

An obvious corollary is that different discretisations  with resulting discretised responses
with resulting discretised responses  will need to satisfy
will need to satisfy

NIFTy is implemented such that in order to change resolution, only the line of code defining the space needs to be altered. It automatically takes care of dependent structures like volume factors, discretised operators and responses. A visualisation of this can be seen in figure 2, which displays the MAP inference of a signal at various resolutions.
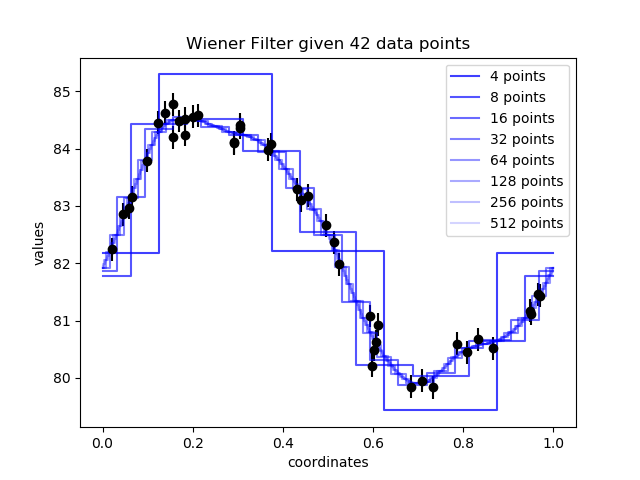
Figure 2: Inference result converging at high resolution.#
Implementation in NIFTy#
Most codes in NIFTy will contain the description of a measurement process or,
more generally, a log-likelihood.
This log-likelihood is necessarily a map from the quantity of interest (a field) to a real number.
The log-likelihood has to be unitless because it is a log-probability and should not scale with resolution.
Often, log-likelihoods contain integrals over the quantity of interest , which have to be discretized, e.g. by a sum

Here the domain of the integral  is the disjoint union over smaller
is the disjoint union over smaller  , e.g. the pixels of the space, and
, e.g. the pixels of the space, and  is the discretised field value on the
is the discretised field value on the  -th pixel.
This introduces the weighting
-th pixel.
This introduces the weighting  , also called the volume factor, a property of the space.
NIFTy aids you in constructing your own log-likelihood by providing methods like
, also called the volume factor, a property of the space.
NIFTy aids you in constructing your own log-likelihood by providing methods like weight(), which weights all pixels of a field with their corresponding volume.
An integral over a Field s can be performed by calling s.weight(1).sum(), which is equivalent to s.integrate().
Volume factors are also applied automatically in the following places:
FFTOperatoras well as all other harmonic operators. Here the zero mode of the transformed field is the integral over the original field, thus the whole field is weighted once.Some response operators, such as the
LOSResponse. In this operator a line integral is discretised, so a 1-dimensional volume factor is applied.In
CorrelatedFieldas well asMfCorrelatedField. Both describe fields with a smooth, a priori unknown correlation structure specified by a power spectrum. The field is multiplied by the square root of the total volume of it domain’s harmonic counterpart. This ensures that the same power spectrum can be used regardless of the chosen resolution, provided the total volume of the space remains the same. It also guarantees that the power spectra in NIFTy behave according to their definition, i.e. the power of a modeis the expectation value of that mode squared, divided by the volume of its space
.
Note that in contrast to some older versions of NIFTy, the dot product s.vdot(t) of fields does not apply a volume factor, but instead just sums over the field components,

where the bar denotes complex conjugation.
This dot product is not invariant under changes in resolution, as then the number of discretised field components increases.
Upper index components like  , however, are designed not to scale with the volume.
, however, are designed not to scale with the volume.
One solution to obtain a resolution independent quantity is to make one of the two factors extensive while the other stays intensive. This is more explicit when intensive quantities are denoted by an upper index and extensive quantities by a lower index,

where we used Einstein sum convention.
Here, the volume metric is incorporated by lowering one index, i.e.  .
When building statistical models, all indices will end up matching this upper-lower convention automatically, e.g. for a Gaussian log-likelihood
.
When building statistical models, all indices will end up matching this upper-lower convention automatically, e.g. for a Gaussian log-likelihood  we have
we have

with the covariance defined by

Consequently, the inverse covariance operator will automatically have lower indices,

ensuring that the whole log-likelihood expression does not scale with resolution. This upper-lower index convention is not coded into NIFTy, in order to not reduce user freedom. One should however have this in mind when constructing log-likelihoods in order to ensure resolution independence.
Harmonic Transform Convention#
In NIFTy the convention for the harmonic transformations is set by requiring the zero mode of the transformed field to be the integral over the original field. This choice is convenient for the Fourier transformation and used throughout the literature. Note that for the spherical harmonics this convention is only rarely used and might result in unexpected factors in the transformed field.
To be specific, for the spherical harmonics transformation this means that a monopole of unit amplitude in position-space which is transformed to the spherical harmonics domain and back to the original position space via the adjoint transformation will have a non-unit amplitude afterwards.
The factor between the input field and the twice transformed field is  .
In comparison to the convention used in HEALPix, this corresponds to dividing the output of the HEALPix transformed field by
.
In comparison to the convention used in HEALPix, this corresponds to dividing the output of the HEALPix transformed field by  in each transformation.
in each transformation.
Depending on the use-case, additional volume factors must be accounted for. This is especially true if one wants to define the inverse transformation. Note that the convention for the harmonic transformations used in NIFTy results in non-unitary operators.